문서 색인
색인 (Indexing)
- 키워드를 입력했을 때 문서를 빠르고 효율적으로 검색하기 위해 문서 집합을 미리 가공하는 작업
- 문서를 검색어 토큰들로 변환하여 데이터가 빠르게 추출될 수 있는 구조로 저장
- 이때 inverted index. 즉, 역색인 구조를 활용.

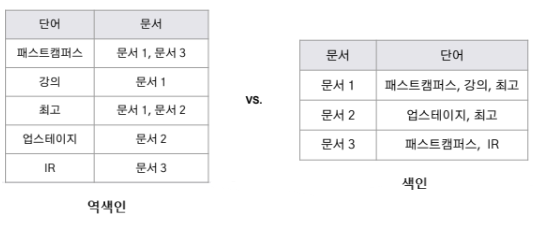
검색엔진의 색인 구조 - 역색인 (Inverted Index)
- 단어가 key 값이 되고, 그 단어가 존재하는 문서들이 value
- 특정 토큰이 어떤 문서와 연관되어 있는지 맵핑되어 있음
- 관련된 문서를 찾는 과정에서 키워드에 해당하는 문서만 추출할 수 있기 때문에 검색 속도가 빠름
역색인을 활용하는 일반적인 색인 단계
1. 텍스트 추출 : 다양한 형식을 가진 문서에서 텍스트를 추출
2. 토큰 추출 : 자연어인 텍스트를 단어 단위로 분해
3. 불용어 (Stop-word) 처리 : 의미를 가지지 않는 관용어, 불용어 등을 제거
4. 정규화 : 표제어 및 어간 추출
5. 역색인 생성
※ 불용어 처리, 정규화 과정을 위해서는 analyze 또는 형태소 분석기가 필요.

토큰화 (Tokenization)
- 문서 또는 질의를 정보의 기본 단위인 단어(토큰)로 나누는 과정
- 문서의 각 토큰은 역색인 데이터 구조에 저장될 key로 사용됨
- 질의의 각 토큰은 역색인 저장소로부터 탐색을 위한 key로 사용됨
- 성능 최적화를 위해 토큰화 이외 추가적인 정보가 필요
- Stop-word 또는 품사 정보 : 검색 성능에 영향이 거의 없지만 메모리와 연산 비용에 부하를 주는 단어 (한국어의 경우 주로 조사)
- Lemmatization : 단어의 표제어 (기본형) 추출 (영어의 경우 형용사 부사의 비교형, 최상급 등)
- Stemming : 용언의 어간 추출
- 복합 명사 정보 (삼성전자 - 삼성 전자 모두를 추출할 것인가? 삼성전자만 추출할 것인가?)
- 동의어 정보 (농협 = NH = 농협은행 = 농협협동조합)
토크나이저 종류
- 공백 기반 토크나이저 (Whitespace Tokenizer)
- 텍스트를 공백 (스페이스, 탭, 줄바꿈 등)을 기준으로 분리
- 대부분의 서유럽 언어에서 효과적이지만, 복합어나 구, 문장부호에 대해서 취약점이 있음
- 규칙 기반 토크나이저 (Rule-based Tokenizer)
- 정규 표현식이나 특정 규칙을 이용하여 텍스트를 분리
- 사전 기반 토크나이저(Dictionary-based Tokenizer)
- 미리 정의된 단어 사전을 사용하여 텍스트를 분리
- 언어의 구조가 복잡하거나 공백으로 단어를 구분하기 어려운 언어(예: 한국어, 중국어, 일본어)에 사용
- 서브워드 토크나이저(Subword Tokenizer)
- 단어를 더 작은 단위(서브워드)로 분리
- BPE(Byte Pair Encoding), WordPiece, SentencePiece 등의 학습 기반 알고리즘
한국어 형태소 분석 이슈
- 한국어의 특성
- 교착어 - 하나의 어근에 여러 형태소가 결합하여 새로운 의미나 문법적 기능을 나타내는 언어
- 다양한 문법적 변화 - 시제, 존댓말, 부정 등이 어미를 통해 표현
- 복합명사와 조사 - 복합명사가 흔하며, 명사는 주로 조사와 붙어서 사용됨
- 중의성 해소의 필요성 - 동일한 철자의 다른 의미를 가지는 단어가 흔함 (문맥에 따른 중의성 해소가 필요)
- 한국어 토큰화 관련 주요 고려 사항
- 복합명사의 처리 방안
- 조사의 처리 방안
- 어간/어미의 처리 방안
대표적인 한국어 형태소 분석기 소개 - 사전 기반
- 은전한닢 (Seunjeon)
- URL: https://eunjeon.blogspot.com/
- 오픈 소스 한국어 형태소 분석기
- Mecab-ko-dic 기반으로 JVM 상에서 구동
- 적당한 품질과 속도
- 노리 (Nori)
- URL: https://www.elastic.co/guide/en/elasticsearch/plugins/6.4/analysis-nori.html
- Elastic에서 2018년 출시 - Elasticsearch에서 공식적으로 지원됨
- 은전한닢에서 만든 mecab-ko-dic 사전을 재가공하여 사용
- 빠른 분석 속도
'AI > NLP' 카테고리의 다른 글
| Evaluation Metric (0) | 2024.04.16 |
|---|---|
| Query-Document Relevance (0) | 2024.04.16 |
| kakaobrain/pororo install in conda (0) | 2024.03.20 |